from multiprocessing import Process
import defs
import os
from colorama import Fore, StylePlaying with multiprocessing
in jupyternotebook
multi-processing will throw error in jupyter notebook; the work around is define your function and then load it back to jupyter as a module;
Use Case
- Wait for a computation to complete before trigger automatically the next step
- A Depth first search algorithmn that let you share common memory of the same computations
Precaution
For multiprocessing to work with jupyter noteboook you have to define your function in modules rather than within the notebook itself;
First Case Map Across Multiple Element
# creating processes
p1 = Process(target=defs.print_square, args=(10, ))
p2 = Process(target=defs.print_cube, args=(10, ))
# starting process 1
p1.start()
# starting process 2
p2.start()Second Case Set a Computation Aside
Basically you can delay executing of some very large functio
pretend
worker1andworker2is two very slow processyou can just setoff
worker1andworker2to start working by itself while you compute something else;to wait for computation to finish you use the
Process.joinmethod;
p1 = Process(target=defs.worker1)
p2 = Process(target=defs.worker2)
# starting processes
p1.start()
p2.start()
# process IDs: those can be worked while wait for completion
print("ID of process p1: {}".format(p1.pid))
print("ID of process p2: {}".format(p2.pid))
# wait until processes are finished
p1.join()
p2.join()
# both processes finished
print("Both processes finished execution!")
# check if processes are alive
print("Process p1 is alive: {}".format(p1.is_alive()))
print("Process p2 is alive: {}".format(p2.is_alive()))ID of process p1: 46583
ID of process p2: 46584
Cube: 1000
Square: 100
ID of process running worker1: 46583
ID of process running worker2: 46584
Both processes finished execution!
Process p1 is alive: False
Process p2 is alive: FalseHere is a mutating variable defs.result defined as a module variable; something intuitive about this is it is a module variable pined to that module; so my function with the global will only ever stop there;
# ./defs.py
result = []
def square_list(mylist):
"""
function to square a given list
"""
global result
# append squares of mylist to global list result
for num in mylist:
result.append(num * num)
# print global list result
print("Result(in process p1): {}".format(result)) mylist = [1,2,3,4]
import defs
defs.result = []
p1 = Process(target=defs.square_list, args=(mylist,))
# starting process
p1.start()
# wait until process is finished
p1.join()
try:
assert defs.result == [1, 4, 9, 16], "The `result` list has not been modified correctly"
except AssertionError as e:
print(Fore.RED + str(e) + Fore.RESET)
print(Fore.RED + str(defs.result) + Fore.RESET)
print(Fore.CYAN + "Now evaluate this function as normal" + Fore.RESET)
defs.square_list(mylist)
assert defs.result == [1, 4, 9, 16]
print(Fore.CYAN + str(defs.result) + Fore.RESET)Result(in process p1): [1, 4, 9, 16]
The `result` list has not been modified correctly
[]
Now evaluate this function as normal
Result(in process p1): [1, 4, 9, 16]
[1, 4, 9, 16]In this example the the result variable has not been changed, because the process don’t share the same memory space?
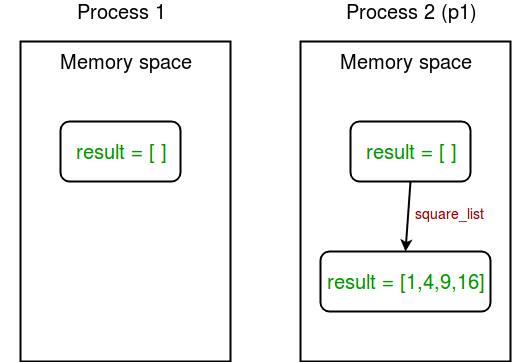
To combat issue with shared memory space you have to use a special multiprocessing object;
import multiprocessing
# creating Array of int data type with space for 4 integers
result = multiprocessing.Array('i', 4)
square_sum = multiprocessing.Value('i')
p1 = Process(target=defs.square_list2, args=(mylist, result, square_sum))
p1.start()
p1.join()
print("Result(in main program): {}".format(result[:]))
print("Sum of squares(in main program): {}".format(square_sum.value)) Result(in process p1): [1, 4, 9, 16]
Sum of squares(in process p1): 30
Result(in main program): [1, 4, 9, 16]
Sum of squares(in main program): 30The Manager
So now the “passive function” modify required object;
# ./defs.py
def print_records(records):
"""
function to print record(tuples) in records(list)
"""
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
"""
function to add a new record to records(list)
"""
records.append(record)
print("New record added!\n") with multiprocessing.Manager() as manager:
# creating a list in server process memory
records = manager.list([('Sam', 10), ('Adam', 9), ('Kevin',9)])
# new record to be inserted in records
new_record = ('Jeff', 8)
# creating new processes
p1 = multiprocessing.Process(target=defs.insert_record, args=(new_record, records))
p2 = multiprocessing.Process(target=defs.print_records, args=(records,))
# running process p1 to insert new record
p1.start()
p1.join()
# running process p2 to print records
p2.start()
p2.join()New record added!
Name: Sam
Score: 10
Name: Adam
Score: 9
Name: Kevin
Score: 9
Name: Jeff
Score: 8
“Que” is a communication object
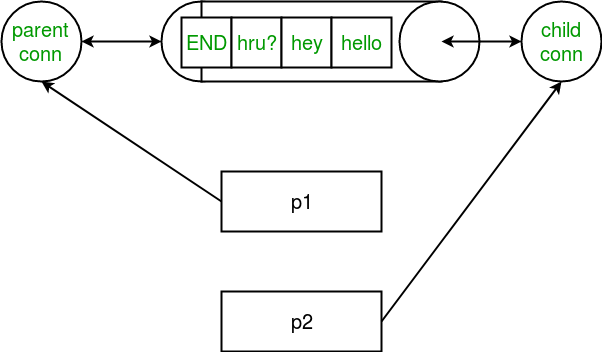
Concept illustartion by geekforgeeks
Use
multiprocessing.Queue
A process can put object by using “que.put”, then then another process can get it “que.get”, but unlike a “dict.get”, “que.get” remove the object from the list;
# creating multiprocessing Queue
q = multiprocessing.Queue()
# access que
# within function
def foo():
q.put()
def bar():
q.get()Example
This example, one function will put stuff in for computation, the other will try access it;
Define following function:
def square_list(mylist, q):
"""
function to square a given list
"""
# append squares of mylist to queue
for num in mylist:
q.put(num * num)
def print_queue(q):
"""
function to print queue elements
"""
print("Queue elements:")
while not q.empty():
print(q.get())
print("Queue is now empty!") Linear Process This process will inject data into que first, and then access it in the scond process
mylist = [1,2,3,4]
# creating multiprocessing Queue
q = multiprocessing.Queue()
# creating new processes
p1 = multiprocessing.Process(target=defs.square_list3, args=(mylist, q))
p2 = multiprocessing.Process(target=defs.print_queue, args=(q,))
# running process p1 to square list
p1.start()
p1.join()
# running process p2 to get queue elements
p2.start()
p2.join()
Square of 1 is 1
Square of 2 is 4
Square of 3 is 9
Square of 4 is 16
Queue elements:
1
4
9
16
Queue is now empty!Lock a Process
multiprocessing.Lock()
This object is used again as outside; you acquire or release it within certain transaction;
# define in function
Lock = multiprocessing.Lock()
# lock within object
lock.acquire()
# >> do stuff uninterupted
locl.release()Explore Asynsio IO
Since javascript have similar process I think this is important API to learn;
Basic usage
use
asyncio.sleep() for development
If you just use the standard time.sleep() the whole process will sleep and there will be no parallel;
use
nest_asyncio for within jupyter notebook for development
Standard pip install. Add this to your jupyter, await will work;
import nest_asyncio
nest_asyncio.apply()A example that don’t quite work;
Simply await an async function in the same process will be as if they are just what they are;
import asyncio
import time
async def main():
await asyncio.sleep(2)
print('hello (taken 2 seconds)')
async def main2():
await asyncio.sleep(1)
print('hello2 (taken 1 second)')
t1 = time.time()
await main()
await main2()
t2 = time.time()
print("The process took {_:.2f} s".format(_=t2 - t1))hello (taken 2 seconds)
hello2 (taken 1 second)
The process took 3.00 sNow let’s try make this work
import nest_asyncio
nest_asyncio.apply()
loop = asyncio.new_event_loop()
tasks = [
loop.create_task(main()),
loop.create_task(main2())
]
t1 = time.time()
loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
t2 = time.time()
print("took {:.2f} s".format(t2-t1))hello2 (taken 1 second)
hello (taken 2 seconds)
took 2.00 sIn multi-processing, this would be:
import time
from importlib import reload
import multiprocessing
import defs
reload(defs)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=defs.long_process1)
p2 = multiprocessing.Process(target=defs.long_process2)
t1 = time.time()
p1.start()
p2.start()
p1.join()
p2.join()
t2 = time.time()
print("took {:.2f} s".format(t2-t1))long_process2 done (taken 1 second)
long_process1 done (taken 3 seconds)
took 3.10 sThe asynsio routine are:
- loop
.new_event_loop(): create a loop object - task
loop.create_task(): create a task from asyncfunction - gather
.gather([Task*]): gather all the tasks - run_until_complete
loop.run_until_complete: run tasks - close
loop.close(): finally close this loop
You can already thinking maybe with a context manager you can take out step1 and step3. But unfortunately there are no context manager for loop object (although there are alternative…hint).
Fortunately a stack user has created one
class OpenLoop:
"""
A context manager for open and close loops;
"""
def close(self,*args, **kwargs):
self._loop.stop()
def _close_wrapper(self):
self._close = self._loop.close # close
self._loop.close = self.close
def __enter__(self):
self._loop = asyncio.new_event_loop()
self._close_wrapper()
return self._loop
def __exit__(self,*exc_info):
asyncio.run(self._loop.shutdown_asyncgens())
asyncio.run(self._loop.shutdown_default_executor())
#close other services
self._close()There is a third way in asyncio
Aysnc task Group
Turn out you don’t create your task loop object, instead you use the default Taskgroup to create tasks that needs to be completed at the same time;
from nest_asyncio import apply
apply()
async with asyncio.TaskGroup() as tg:
taskA = tg.create_task(main())
taskB = tg.create_task(main2())
t0 = time.time()
A = await taskA
B = await taskB
t1 = time.time()
print("-"*50)
print(f'Time taken: {t1-t0:.2f} seconds')
print("-"*50)hello2 (taken 1 second)
hello (taken 2 seconds)
--------------------------------------------------
Time taken: 2.00 seconds
--------------------------------------------------Passive Perk: Auto Caching within same loop
Another perk I have found is that async function will not recalculate your reuslt
import pandas as pd
def make_A_normal():
return pd.DataFrame({'A': [1, 2, 3]})
def make_B_normal():
return pd.DataFrame({'B': [4, 5, 6]})
async def make_A_async():
await asyncio.sleep(1)
return make_A_normal()
async def make_B_async():
await asyncio.sleep(2)
return make_B_normal()
print(f'type(make_A_normal): {type(make_A_normal)}')
print(f'type(make_A_async): {type(make_A_async)}')
# first way to do it is just create a singular task
with OpenLoop() as loop:
tasks = [ loop.create_task(make_A_async())
, loop.create_task(make_B_async())]
# call it till complete
t0 = time.time()
A, B = loop.run_until_complete(asyncio.gather(*tasks))
t1 = time.time()
print("-"*50)
print(f'Time taken: {t1-t0:.2f} seconds')
print("-"*50)
print("\nNow lets try do it again with a for loop")
t0 = time.time()
for task in tasks:
await task
t1 = time.time()
print("-"*50)
print(f'Time taken: {t1-t0:.2f} seconds')
print("-"*50)type(make_A_normal): <class 'function'>
type(make_A_async): <class 'function'>
--------------------------------------------------
Time taken: 2.00 seconds
--------------------------------------------------
Now lets try do it again with a for loop
--------------------------------------------------
Time taken: 0.00 seconds
--------------------------------------------------Looking at above! The second time took zero second!
Apply this to my Stagemanager
OPTION 1: Use multiprocess.Manager
Wrap my function in lambda for each target? We can see if we can wrap a dataframe in manager; the talk about manager maybe suited for processing two different dataframe? or any object?
OPTION 2: Could apply_async maybe something better to use just simply within each stage?
So far all my function resulted in somewhere else?
from multiprocessing import Pool
pool = Pool()
result1 = pool.apply_async(solve1, [A]) # evaluate "solve1(A)" asynchronously
result2 = pool.apply_async(solve2, [B]) # evaluate "solve2(B)" asynchronously
answer1 = result1.get(timeout=10)
answer2 = result2.get(timeout=10)OPTION 3: Use Component Graph to split into several process and then combine them back?
Also its possible to split into component? That means there needs to be a method to convert the dependency graph into a Chain object.
OPTION 4: The asyncio implementation; that means we either have to write everything in await style, or def as normal let the python do the conversion;
Concerning multi-processor’s memeory management system;
One drawback with multi-processor to me is share any class variables easily between different tasks don’t seems as inuitive. A lot of give example will use python global scoping varible to demo; For understanding, I have to revisit python global variable scoping (I don’t want when I create a package, those passive function will refuse to modify the variable I want to modify correctly);
Revisiting Python Global Variable Scoping:
- …if referencing variable outside function, it is okay (READONLY)
- ..to modify a variable outside function, you have to use the keyword global.
- …but for mutable oject such as class, list dict you dont need specify global
I’m not clear with how multi-processor produce a output variable and pass it to the next processor? right now it seems multi-processor is good for when you have a database and multiple user is trying to access this database?
The best use case I can think of (involve passive function) is when you have a data pipeline run in cloud and bucket, and you would want those data pipeline to run in order, and directly mutate the object in a particular order (use que and lock) – indeed, because copying the staging variable around could potentially cause a lot of data transfer/storage cost?
Paral computing with Async/Await The syntax is very demure… but in somecases it don’t work as parallel, you have to await a task; hint:
asyncio.gather|>loop.run_until_completeawait task,task = asyncio.create_task()You also have to be carful because the you cannot process a sub fork by default.
My real problem is DAG README from the open-source package to acheive this ?@sec-mayromr-async-dag , explain this really well (there is a issue with typing [^2] the package author has to use a lot of redundant code of typing things).
Use Edge Table For Parsing
from fztools import StageManager
stage1 = StageManager("stage1")
stage2 = StageManager("stage2")
@stage1.register("A")
def plus_one(a):
return a + 1
@stage1.register("B")
def power_two(b):
return b * b
@stage2.register("C", ["A", "B"])
def sum_all(a, b):
return a + b
chain = stage1 >> stage2
chain.input = {"A": 1, "B": 2}
chain.invoke()
chain.output
chain.edge_table| source_id | source_ele | target_id | target_ele | |
|---|---|---|---|---|
| 0 | 0 | <function plus_one at 0x10660aac0> | 0 | A |
| 1 | 0 | <function power_two at 0x10660a160> | 0 | B |
| 2 | 1 | <function sum_all at 0x10660aa20> | 1 | C |
| 0 | -1 | A | 0 | <function plus_one at 0x10660aac0> |
| 1 | -1 | B | 0 | <function power_two at 0x10660a160> |
| 2 | 0 | A | 1 | <function sum_all at 0x10660aa20> |
| 2 | 0 | B | 1 | <function sum_all at 0x10660aa20> |
chain.as_table()| stage_id | stage_name | output | prev_stage_id | inputs | func | |
|---|---|---|---|---|---|---|
| 0 | 0 | stage | A | -1 | [A] | <function plus_one at 0x10660aac0> |
| 1 | 0 | stage | B | -1 | [B] | <function power_two at 0x10660a160> |
| 2 | 1 | stage | C | 0 | [A, B] | <function sum_all at 0x10660aa20> |
stgs = chain.stages
for stg in stgs:
print(stg.funcs)
print(stg.funcs_args){'A': <function plus_one at 0x10660aac0>, 'B': <function power_two at 0x10660a160>}
{'A': ['A'], 'B': ['B']}
{'C': <function sum_all at 0x10660aa20>}
{'C': ['A', 'B']}There are a few problem with this method; both because variable without a function registered will pass on as it is… But from as_table we can attempt to parase assign type;
import asyncio
def make_async_stage(stage):
funcs = stage.funcs
funcs_args = stage.funcs_args
async_stage_funcs = {}
for key, func in stage.funcs.items():
async def async_func(*args,**kwargs):
return func(*args,**kwargs)
async_stage_funcs[key] = async_func
return async_stage_funcs
input_dict = {"A": 1, "B": 2}
result = {}
async_stage_funcs = make_async_stage(stage1)
async with asyncio.TaskGroup() as tg:
for key, async_func in async_stage_funcs.items():
print(type(async_func))
arg = input_dict[key]
task = tg.create_task(async_func(arg))
d = await task
result[key] = d
result<class 'function'>
<class 'function'>{'A': 1, 'B': 4}Now the problem became, how to wrap an unevaulated expectation? (Future)
from nest_asyncio import apply
apply()
async def set_after(fut, delay, value):
# Sleep for *delay* seconds.
await asyncio.sleep(delay)
# Set *value* as a result of *fut* Future.
fut.set_result(value)
async def main():
# Get the current event loop.
loop = asyncio.get_running_loop()
# Create a new Future object.
fut = loop.create_future()
# Run "set_after()" coroutine in a parallel Task.
# We are using the low-level "loop.create_task()" API here because
# we already have a reference to the event loop at hand.
# Otherwise we could have just used "asyncio.create_task()".
loop.create_task(
set_after(fut, 1, '... world') )
print('hello ...')
# Wait until *fut* has a result (1 second) and print it.
print(await fut)
asyncio.run(main())hello ...
... worldThe One I Need!
Finally I have found a menimum example of establish coroutine based on something is done or not; This technical is essential dfs search all at the time;
from random import randrange
# Helper function for the creation of simple sample coroutine
def make_sample_coro(n):
async def coro():
print(f"Start of task {n} ...")
await asyncio.sleep(randrange(1, 5))
print(f"... End of task {n}")
return coro
async def main():
# Simple graph in standard representation (node => neighbours)
graph = {1: {2, 5}, 2: {3}, 3: {4}, 4: set(), 5: {4}}
tasks = {n: make_sample_coro(n) for n in graph}
tasks_done = set()
async def execute_task(ID):
print(f"Trying to execute task {ID} ...")
predecessors = {n for n, ns in graph.items() if ID in ns}
while not predecessors <= tasks_done: # Check if task can be started
await asyncio.sleep(0.1)
await tasks[ID]()
tasks_done.add(ID)
await asyncio.gather(*[execute_task(n) for n in graph])
print("... Finished")
await main()
Trying to execute task 1 ...
Start of task 1 ...
Trying to execute task 2 ...
Trying to execute task 3 ...
Trying to execute task 4 ...
Trying to execute task 5 ...
... End of task 1
Start of task 2 ...
Start of task 5 ...
... End of task 5
... End of task 2
Start of task 3 ...
... End of task 3
Start of task 4 ...
... End of task 4
... FinishedNote that this is not a chain; because each node are run at the same time, so actually you only need to search the dependency up one level!
It does not explicitly identify the graphical root; The root 1 would not have a dependency;
# to esplain the set operator;
assert {1} <= {1,2,3}
assert {1,2,3} <= {1,2,3}
assert ({1,2,3,4} <= {1,2,3}) == FalseReference
Event Loop Runtime Error – came across this when try run sample code in jupyter notebook;
Async Await Demo: key takeaway is when writing a demo its better to use the
async.sleepfor time pulse.mayromr Development Async DAG library: mayromr/async-dag: A simple library for running complex DAG of async tasks
- A side issue of this is typing TypeVarTuple Transformations Before Unpack · Issue #1216 · python/typing